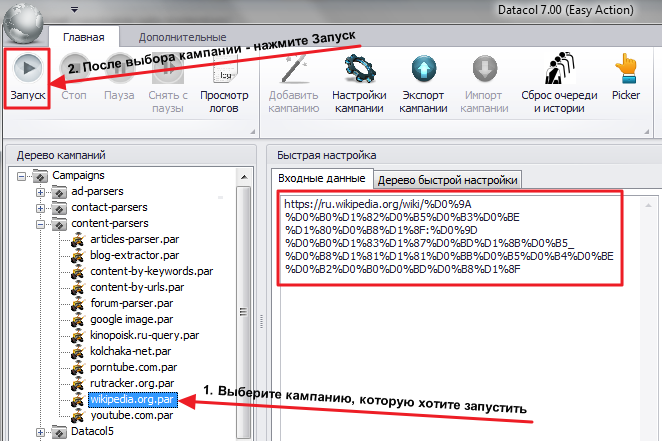
Связанные ссылки в html - Parser Википедия

Как реализовать парсинг Википедии на Java?
Извлечение текста из википедии Помогите, пожалуйста, с задачкой. Нужно реализовать следующее: Вбивается название страны, и со Найти кратчайший путь по страницам википедии Пользователь задаёт начальную и конечную страницу википедии, из начальной в конечную можно попасть Парсинг википедии Здравствуйте, знатоки! Помогите со следующим заданием, пожалуйста!













🐍 Самоучитель по Python для начинающих. Часть 17: Основы скрапинга и парсинга
Привет, друзья. Сегодня я хочу поделиться еще одной наработкой из большого списка регламентов и инструкций нашей студии «АлаичЪ и Ко». Среди моих коллег есть фанат работы с Гугл Таблицами — это Алексей Степанов, совместно с которым мы готовили для вас прошлую публикацию про написание seo-текстов и подготовки ТЗ для копирайтеров.
- Navigation Menu
- Чтобы получить заголовок веб-страницы, используйте Python совместно с библиотеками requests и BeautifulSoup. Убедитесь, что в вашем окружении Python установлены библиотеки requests и beautifulsoup4.
- Тема в разделе " Делимся опытом ", создана пользователем Iura , 8 янв A-Parser - парсер для профессионалов SEO.
- Uniform Resource Identifier — унифицированный единообразный идентификатор ресурса. URI — последовательность символов, идентифицирующая абстрактный или физический ресурс.
- Подробнее об извлечении определённых элементов
- Веб-скрапинг — это процесс автоматического сбора информации из онлайн-источников.
- Skip to content. You signed in with another tab or window.
- Skip to content.
- Установка и использование
- Время от времени разработчикам необходимо парсить веб-страницы, чтобы получить некоторую информацию с какого-нибудь веб-сайта.
- Она работает с вашим любимым парсером, чтобы дать вам естественные способы навигации, поиска и изменения дерева разбора.
- Файл обрабатывается построчно, пустые строки игнорируются.









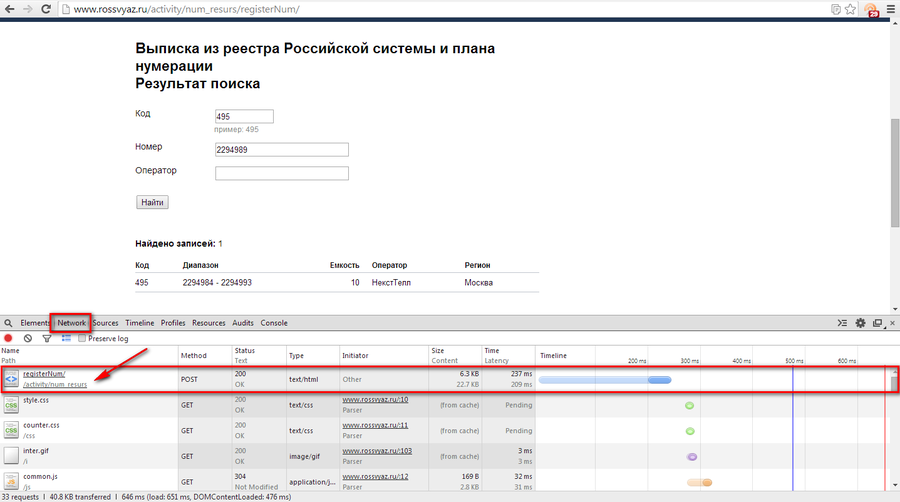

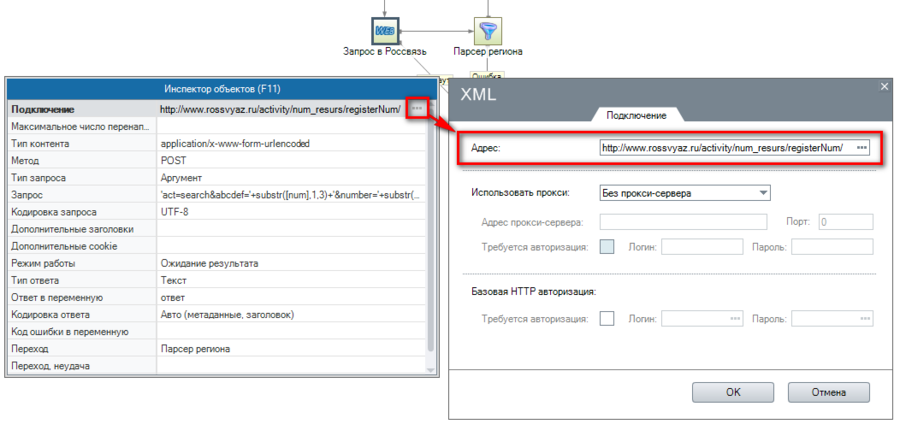
Следуйте за нами на Мастодоне и других социальных сетях. Конфиденциальность англ. Синтаксические плагины — это плагины расширения синтаксиса « ДокуВики ».